Import a website with Site Crawler
The site crawler is a straightforward tool that allows Pro, Team, and Agency users to import an existing public website as a sitemap.
* Note that it does not support password-protected sites or intranets.
To import a Slickplan XML file, just follow these simple steps:
From the import panel
- In Slickplan, open an existing project.

- Click the Import icon in the navigation bar (this will overwrite your current sitemap).

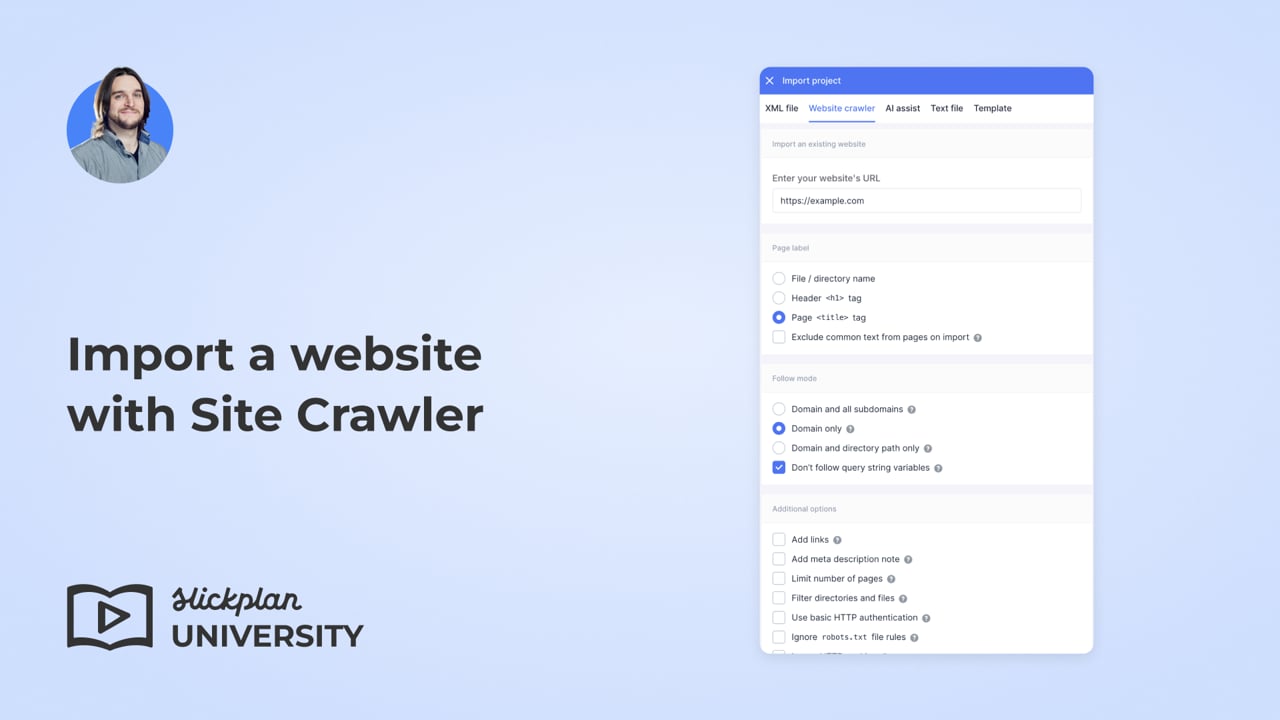
- In the import panel, select the Website crawler tab.

- Type your website’s full URL in the text box.

- Select the options below for the sitemap page text, follow mode, and extra options.
- Page text:
- File/directory name to use URL’s (page and/or folder name) as the page label.
- Header <h1> tag to use the main header text from your webpage as the page label.
- Page <title> tag to use the page title from your webpage as the page label.
* Check the Exclude common text from pages on import option. This will remove repetitive text. For instance, you can eliminate recurring SEO phrases like “| Company Name” that appear before or after the title.
- Follow Mode:
- Domain and subdomains: To crawl both the domain and its subdomains, enter a URL (e.g.,
https://example.com). Our Site Crawler will then fetch pages from example.com and all its subdomains, likefoo.example.comandbar.example.com. - Domain only: If you want our Site Crawler to follow links only from the specified domain, such as
example.comandwww.example.com. - Domain and directory path only: This option limits the Site Crawler to a specific domain and directory path. For example, if you enter
https://www.example.com/dir/, it will only follow links that start with that path, like
https://example.com/dir/. - Don’t follow query string variables – will exclude links containing
?and&characters, for example:https://example.com/link?param=1&page=2. This option is helpful if you have many pagination pages or dynamically generated calendar.
- Options:
- Add links: Include a URL for imported pages.
- Add meta description: Insert a note with content from the meta description tag.
- Limit number of pages: Set the maximum number of pages the import tool can fetch. For example, entering 10 will download up to 10 pages from the website.
- Filter directories: Choose specific directories to include or exclude from the crawl.
Enter a directory name followed by/*in either of the text area boxes.
Press return(enter) to add more directories; you can add as many as you need. - Basic HTTP authentication: If your website is password-protected, enter your username and password. (Note: This currently works only with the HTTP Basic Auth method)
- Ignore robots.txt rules: Choose this option if your server blocks web crawlers from accessing your website.
- Ignore HTTP cookies: Ignores any cookies your website attempts to store.
- Use a custom user agent string: Some websites block anything with “crawler” in the name. This option defaults to your browser’s name, helping our crawler appear as a real browser to avoid firewall blocks.
- Import SEO meta data to Content Planner: Imports SEO details, including metadata and URL slugs, for each page into the Content Planner tool.
- Render JavaScript content: Includes dynamic content generated by JavaScript.
- Import into a section: This lets you add your website to a specific sitemap page as a new branch without overwriting the whole project.

- Click Import to complete the process.

During project setup
- Create a new project.
- Enter the URL into the field under the project name and check the Import from URL option below.

- Click the Next, add People button.

- Add team members and click Create project.

- The new project will open with the import panel expanded and prepopulated with the provided URL. Set additional import settings and hit Import.

Troubleshooting issues: Limits and quick fixes
Below are the key steps for monitoring progress, overcoming crawling limitations, and finalizing your sitemap, along with essential subscription requirements and security considerations.
Sitemap creation process
Building your sitemap
Depending on the size of your site, it may take a few minutes for your sitemap to build. The number on the import screen indicates how many pages have been downloaded. For instance, “Gathering Links (13)” means the crawler has scanned 13 pages so far.
Monitoring progress
If you don’t see any progress after a few minutes, click the Cancel button and try again. You can also stop the crawling process manually by clicking the Stop & Save button, which will generate a sitemap based only on the pages successfully scanned.
Crawling limitations
Keep in mind that the crawler can only access publicly available websites. It cannot crawl intranet sites or those requiring custom authentication, such as username and password logins.
Multi-tasking during crawling
While the crawler is working, you can close the browser window, edit another sitemap, or crawl a different website.
Finalizing your sitemap
You have now built a sitemap using the site crawler, and it is ready for editing and customization!
Subscription note
The site crawler feature is available only to users with Pro, Team, and Agency subscriptions.
Security note
For security reasons, the crawler is limited to 10,000 pages per process.